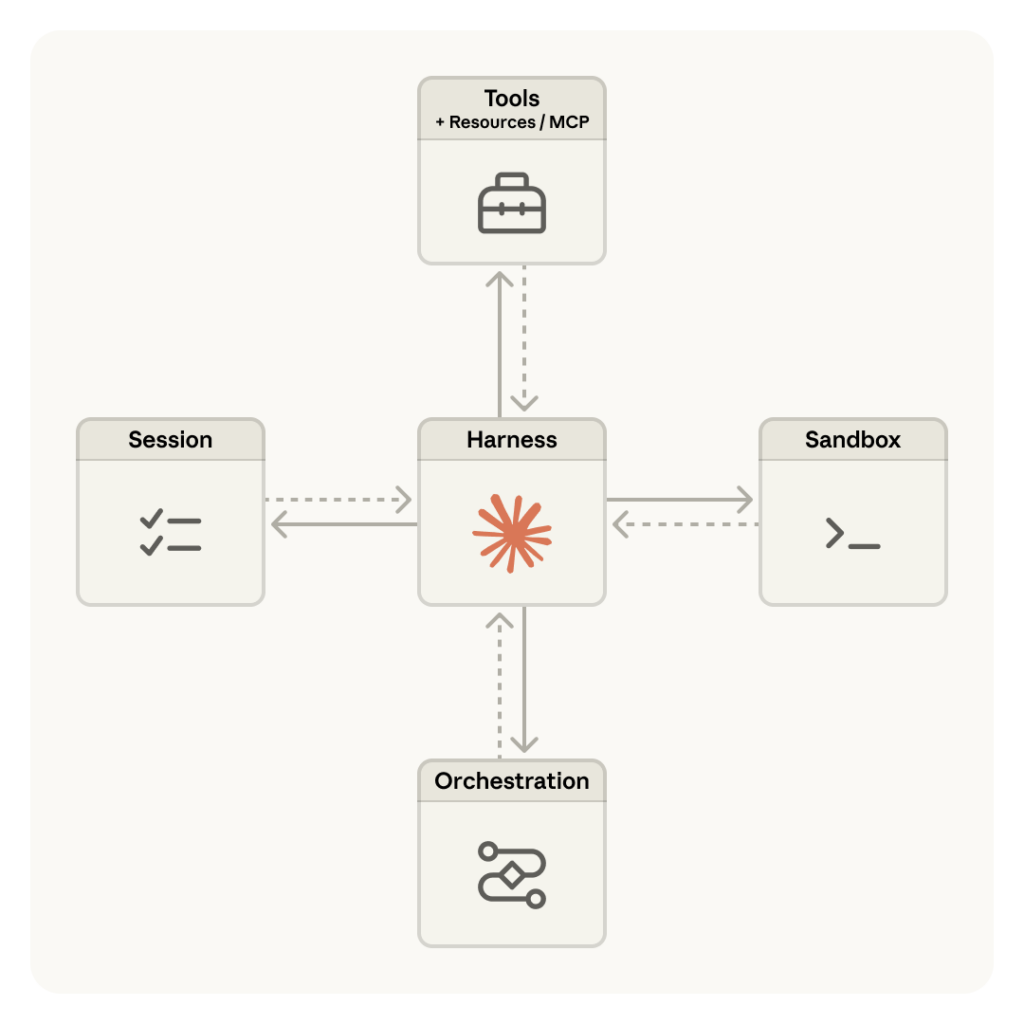
當企業開始把 AI 從聊天介面推進到實際流程,真正的瓶頸往往不在模型本身,而是在執行環境、工具權限、狀態保存、觀測能力與失敗恢復。這也是為什麼 Anthropic 最新推出的 Claude Managed Agents 值得注意:它不只是把 Claude 包成一個「會用工具的聊天模型」,而是把 agent 執行所需的 harness 與基礎設施,變成一套可託管、可擴充、可觀測的執行平台。
從 Anthropic 於 2026 年 2 月 4 日 發表的工程文章,到目前官方文件要求的 managed-agents-2026-04-01 beta header,以及 2026 年 4 月 8 日 發布的官方 tutorial 來看,Claude Managed Agents 的定位已經非常明確:它是給長時間、多步驟、需要工具與容器支援的 enterprise agent 工作流使用,而不是單純取代一般的 Messages API。
什麼是 Claude Managed Agents?
依照 Anthropic 官方文件的描述,Claude Managed Agents 是一套 pre-built、可配置、運行於託管基礎設施上的 agent harness。開發團隊不需要自己從零實作 agent loop、sandbox、工具執行層與長任務狀態管理,就能直接讓 Claude 在受控環境中讀檔、寫檔、執行命令、搜尋網頁、呼叫 MCP 工具,並以事件流方式持續回傳執行進度。
官方把整體架構拆成四個核心概念:Agent、Environment、Session 與 Events。這種設計讓企業可以把「模型設定」、「容器環境」、「單次任務執行」與「執行事件紀錄」分開管理,也讓後續的權限控管、追蹤、除錯與成本治理更容易制度化。
為什麼企業現在該注意?
1. 從模型 API,走向託管式 agent runtime
如果任務只是單輪摘要、分類、QA 或簡單函式呼叫,Messages API 往往已經足夠;但當任務變成「要跑幾分鐘到幾小時、要讀寫多個檔案、要跨工具多步驟執行、過程中還可能被中斷或改方向」,企業真正需要的就不只是模型,而是一個可靠的 agent runtime。Claude Managed Agents 正是在填這一層。
2. 把長任務的狀態保存,從 prompt 技巧升級為平台能力
Anthropic 在工程文章裡很強調一件事:長流程 agent 的核心問題,不只是 context window 大小,而是如何把任務狀態、工具輸出與執行歷程保存成可恢復、可重讀、可追蹤的 session。Managed Agents 以事件流保存 session 狀態,讓 harness 或執行器失敗時能重新喚醒,這比單靠 prompt compaction 或手工摘要,更接近企業可接受的正式系統設計。

3. 安全邊界比傳統 agent harness 更清楚
在許多自建 agent 架構裡,模型產生的程式碼、工具憑證與執行環境常常被塞在同一個容器內,這代表一旦碰到 prompt injection 或工具濫用,風險會直接擴大。Anthropic 在官方工程文章中指出,Managed Agents 的設計目標之一,就是讓憑證不要暴露在 Claude 實際執行生成程式碼的 sandbox 裡。像 Git 權限、MCP/OAuth 存取,都盡量透過資源初始化、proxy 與 vault 方式處理,而不是把秘密直接放進可執行環境中。
4. 效能與擴展性,不再綁死在單一容器
Anthropic 把這套架構稱為「decoupling the brain from the hands」:把 Claude 與 harness 這個「brain」,從 sandbox 與工具這些「hands」解耦。這樣的結果是,容器不需要在每個 session 一開始就全部啟動,只有需要時才被喚起。官方數據指出,改成這種設計後,p50 TTFT 約下降 60%,p95 降幅超過 90%。對企業來說,這代表更好的首回應速度,也代表更容易把 agent 擴張到多個任務與多個執行環境。
5. 可觀測性終於成為第一級能力
Claude Managed Agents 採用 event-based communication。你的系統不是只收到最終答案,而是能看到使用者事件、agent 事件、session 事件與 span 級別的執行紀錄。官方文件也提供 Console tracing 與 raw event retrieval,讓團隊能追 session error、工具調用結果、token 使用量與中途停下來等待批准的狀態。對要上線到企業流程的 AI Agent 而言,這一層比「模型答得多漂亮」更重要。
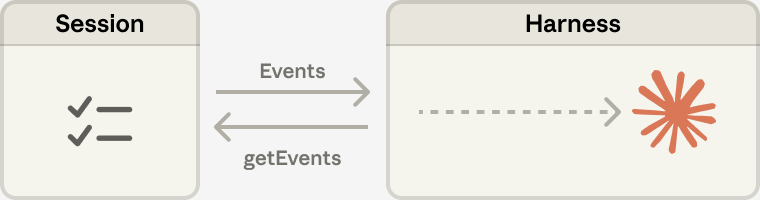
6. 後續路線圖也很清楚:multiagent、memory、outcomes
目前官方文件已經把 multiagent、memory 與 outcomes 列為 research preview。這代表 Anthropic 想做的不是單一 agent demo,而是把多代理協作、跨 session 記憶與任務目標管理逐步整合進統一的平台模型。對企業來說,這很關鍵,因為真正的 agent 導入很少只是「一個 prompt 做完一件事」,而更常是多角色、多工具、多狀態的長流程協作。
這和 Nexra 的服務有什麼關係?
AI Agent / OpenClaw 工作流設計
從 Nexra 的角度來看,Claude Managed Agents 代表一個很實際的訊號:未來企業導入 agent,不一定都要自己從零搭完整 harness。若任務本質是雲端執行、長流程、強依賴工具與狀態保存,採用託管式 agent platform 能明顯降低開發與維運門檻;而在需要內部流程設計、工具編排、權限策略、fallback 邏輯與人機分工的部分,依然需要像 Nexra 這樣的團隊做流程設計與系統整合。
企業 AI 系統整合
Claude Managed Agents 本身提供的是執行平台,不會自動幫企業完成 CRM、ERP、文件系統、知識庫、簽核流程與白名單網路的整合。真正落地時,仍然需要定義哪些操作可以自動做、哪些動作需要人工批准、哪些工具應該經由 MCP 暴露、哪些事件要回寫到內部系統。這正是企業 AI 系統整合的核心工作,也是 Nexra 能發揮價值的地方。
RAG 與記憶治理
Anthropic 官方已經開始提供 memory store 的研究預覽能力,但企業在知識治理上通常不會只依賴 agent memory。更穩定的做法,往往是把 RAG 知識庫、文件權限、版本控管與任務記憶分層處理。對 Nexra 來說,Claude Managed Agents 很適合成為上層執行器,而 RAG、文件索引與權限治理則仍應由企業既有資料策略與 AI 架構共同支撐。
LLM 推理 API 仍然有位置
這篇也提醒我們,並不是所有任務都該直接上 Managed Agents。如果業務需求只是穩定的分類、摘要、客服、知識問答或單步驟 API 回應,那麼傳統的 LLM 推理 API 往往更簡單、更便宜、也更容易治理。Managed Agents 真正適合的是需要長任務、工具調用、狀態保持與中途交互的流程型工作。換句話說,它不是取代 API,而是補上 API 之上的 agent runtime 層。
企業導入前,建議先評估這幾件事
- 任務是否真的需要長流程 agent? 如果只是短回合推理,未必需要引入託管式 agent 平台。
- 哪些工具能開放,哪些一定要人工批准? 先定義 permission policy,比事後補救來得重要。
- 是否需要與企業內網、VPC、MCP 或既有系統串接? 平台能力只是起點,整合設計才是真正的落地工程。
- 事件流與 observability 要怎麼接進既有監控? session tracing、error event、token usage 都應納入正式維運視角。
- 要用 memory,還是用 RAG,還是兩者分工? 這會直接影響資料治理與風險控制方式。
- 成本與回應時間是否符合業務場景? 託管 agent 平台降低開發複雜度,但仍需要做好工作流分層與成本治理。
結語
Claude Managed Agents 的真正價值,不在於「Claude 又多了一個新功能」,而在於 Anthropic 正把 agent 所需的執行平台能力標準化:包含長流程 session、受控容器、工具調用、事件流、可觀測性與後續的 multiagent / memory 擴展。對企業來說,這會讓 AI Agent 更像一個可以正式上線的系統元件,而不只是 demo。
如果你的團隊已經在評估 AI Agent、RAG、工作流自動化或企業內部系統整合,Nexra 可以協助你判斷哪些需求適合直接使用託管式 agent 平台,哪些環節仍需要自建流程、治理層與系統整合,讓 AI 從可展示的原型,真正走向可營運的產品能力。
資料來源:Anthropic Engineering: Scaling Managed Agents: Decoupling the brain from the hands、Claude API Docs: Claude Managed Agents overview、Claude API Docs: Session event stream、Claude Cookbook: Managed Agents tutorial: iterate on a failing test suite。