如果說企業在評估封閉式商用模型時,最在意的是能力與可用性,那麼在評估開放模型時,真正關鍵的往往是另外幾件事:能不能私有化部署、能不能跑在自己掌握的硬體上、能不能支援 Agent 工作流、能不能在延遲與成本之間取得平衡。從這個角度看,Google DeepMind 於 2026 年 4 月 2 日發布的 Gemma 4,不只是新一代開放模型,而是一個更貼近企業自建與本地部署需求的模型家族。
Gemma 4 是什麼?
Gemma 4 是 Google DeepMind 推出的新一代開放模型系列,官方定位是「byte for byte 最有能力的開放模型」。它延續 Google 在 Gemini 系列上的研究能力,但以開放權重與更高的部署彈性為核心,讓開發者與企業可以在自有環境中使用、調校與部署。
根據官方文章,Gemma 4 目前提供四種主要尺寸:E2B、E4B、26B MoE 與 31B Dense。這四種型號不是單純參數大小不同,而是對應不同的硬體條件與應用場景,從手機、IoT 裝置、筆電 GPU,到單張 H100 與企業級推理伺服器,都有相對應的模型選項。
企業視角下,Gemma 4 值得注意的幾個特性
1. Apache 2.0 授權,更適合企業做私有化與商業化部署
Google 在 Gemma 4 上特別強調 Apache 2.0 授權。對企業來說,這件事非常重要,因為它直接影響模型能否在商業產品、內部系統、私有雲與地端環境中安心使用。當企業希望保有資料主權、基礎設施控制權與模型調校自由度時,Gemma 4 這類授權友善的開放模型會比限制較多的方案更容易落地。
2. 從手機到 H100,都有可對應的模型尺寸
Gemma 4 不是只為大型 GPU 機房設計。Google 官方指出,E2B 與 E4B 版本是偏向 edge 與 mobile-first 的模型,可在手機、Raspberry Pi、Jetson Orin Nano 等裝置上離線執行;26B 與 31B 則更適合研究、開發與高品質推理場景,其中未量化的 bfloat16 權重可在單張 80GB H100 上運行,量化版本則可落到消費級 GPU。這種尺寸分布,對企業做分層部署非常有價值。
3. 原生支援 Agent 工作流
Gemma 4 不是只拿來做一般問答。Google 官方明確提到它支援 function calling、結構化 JSON 輸出與原生 system instructions,這些能力對 Agent 應用非常關鍵。因為一旦模型要接工具、打 API、做步驟型任務、產出可機器解析的結果,這些能力就不再是加分項,而是能不能進入正式流程的基本條件。
4. 多模態、長上下文與多語言能力更適合企業資料
Gemma 4 全系列原生支援圖片與影片理解,E2B 與 E4B 另外支援原生音訊輸入。上下文部分,edge 版本支援 128K,大型版本最高可到 256K。語言方面,官方提到模型原生訓練涵蓋超過 140 種語言。對企業而言,這表示它不只適合文字問答,還更適合處理文件、圖表、OCR、多語內容與跨部門知識資料。
5. Intelligence-per-parameter 對成本與效能更有意義
Gemma 4 的一個重點不是把模型做得更大,而是提高每一單位算力所能換到的能力。Google 官方文章指出,截至 2026 年 4 月 1 日,31B 版本在 Arena AI 開源文字模型榜上排名第 3,26B 版本排名第 6;其中 26B MoE 在推理時只啟動約 3.8B 參數,特別偏向低延遲與更快的 tokens-per-second。對企業來說,這種設計比單看總參數更實用,因為它直接影響部署成本與實際可用性。
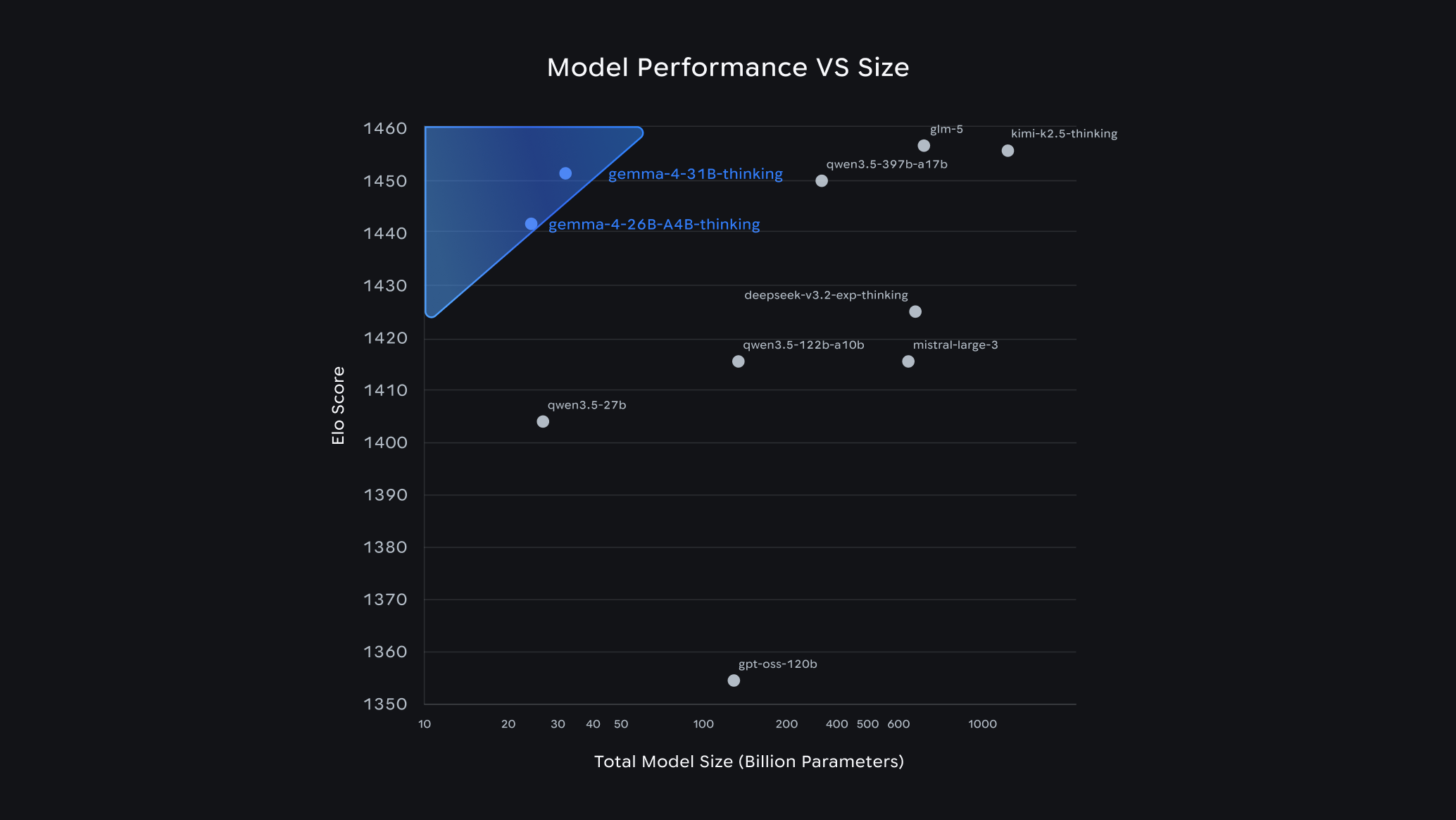
如果放到 Nexra 的服務場景,Gemma 4 可以怎麼用?
獨佔 GPU 虛擬機 / 私有化部署
Gemma 4 很適合作為私有化部署與專屬推理環境的候選模型。若企業在意資料不外流、模型要留在內網、需要白名單或 VPN 管理,Gemma 4 的開放權重與授權條件會比很多封閉模型更容易設計落地方案。對 Nexra 這類提供獨佔 GPU 虛擬機與私有化部署能力的服務來說,Gemma 4 也是很適合搭配專屬環境做長期運營的模型。
LLM 推理 API 月租代管
對不想自己維運推理堆疊的團隊,Gemma 4 也可以包裝成企業內部或對外服務的推理 API。尤其是 26B 與 31B 這類模型,若部署在專屬 GPU VM 上,再搭配快取、權限、紀錄與配額控管,就能形成穩定的內部 API 層。這對需要固定成本、可預估效能、又希望保留模型自主權的團隊來說非常實用。
AI Agent / OpenClaw 工作流
Gemma 4 對 Agent 場景很有吸引力,因為它官方就把 function calling、JSON 輸出與 agentic workflows 當成核心能力。這與 Nexra 的 AI Agent / OpenClaw 工作流方向高度吻合。企業可以用它來做研究助理、工具串接、自動報表、內部任務代理與跨系統流程執行,讓模型不只是回覆問題,而是真的參與工作流程。
RAG 與多模態知識庫
Gemma 4 不只適合當聊天模型,也適合做知識檢索與文件理解。當企業資料包含 SOP、技術文件、規格書、圖片截圖、圖表或掃描件時,多模態能力與長上下文就會很重要。若再配合向量資料庫與權限設計,Gemma 4 可以成為企業內部知識庫、客服問答與專案輔助系統的推理核心。
邊緣 AI 與離線場景
Gemma 4 相比很多大型雲端模型,一個很不一樣的優勢是 edge deployment。若企業有門市、工廠、現場作業、行動裝置或不穩定網路環境,E2B 與 E4B 這類模型就有機會支撐更低延遲、可離線、資料不出端的應用。這對需要現場即時回應的內部工具與垂直流程,很有實際價值。
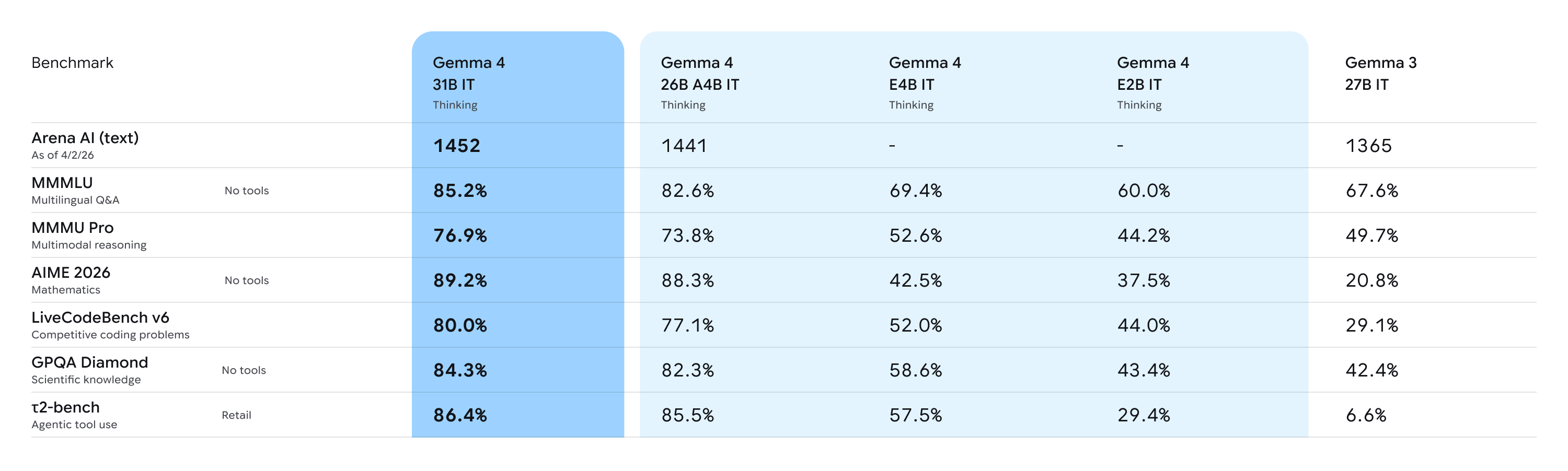
導入 Gemma 4 之前,企業應該先想清楚什麼?
- 先選部署模式,再選模型尺寸:如果目標是本地端、行動端或邊緣裝置,E2B / E4B 才是重點;如果目標是高品質推理、RAG 與 Agent,26B / 31B 更值得優先評估。
- 不要只看總參數,要看實際硬體成本:企業最終要負擔的是 GPU、記憶體、延遲與維運,而不是模型名稱本身。Gemma 4 的優勢之一,就是比較容易做硬體分級配置。
- Agent 與 RAG 要一起驗證:如果未來目標是工具呼叫或知識庫工作流,測試集就不能只做問答,而要驗證 JSON 結構、工具穩定性、長文件理解與多步驟流程。
- 開放模型仍需要治理與安全設計:即使模型能私有化,也不代表可以省略權限設計、審計紀錄、輸出驗證與敏感資料保護。真正的企業落地,還是要把模型放進受控架構中。
結語
Gemma 4 的價值,在於它把「開放模型」從研究型選項往正式部署方案推進了一步。它同時具備開放授權、硬體彈性、多模態能力、Agent 工作流支援與邊緣部署可能性,對想要自建、私有化、控制成本又保留模型主導權的團隊來說,是非常值得關注的新選項。
如果你的團隊正在評估開放模型該怎麼落地,Nexra 可以協助你從模型選型、獨佔 GPU 虛擬機、私有化部署、推理 API 月租代管,到 AI Agent 與企業系統整合,規劃一條真正能進入正式環境的導入路徑。
註:本文中的模型資訊與圖片整理自 Google 官方 Gemma 4 文章,並以企業導入與系統整合角度重新編寫。原始參考文章:Gemma 4: Byte for byte, the most capable open models。