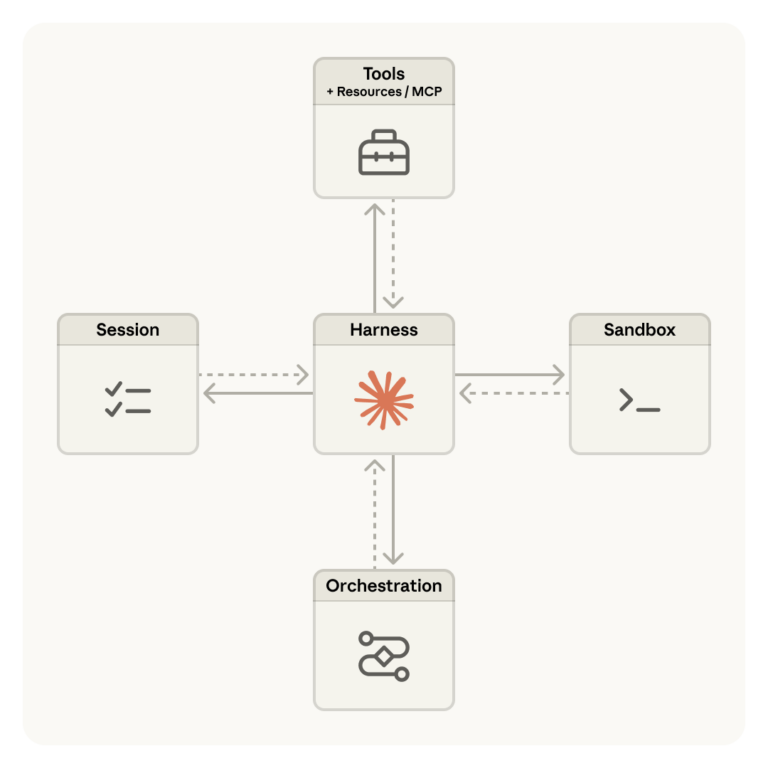
Anthropic 於 2026 年 5 月 28 日 正式發布 Claude Opus 4.8。這次更新不是單純的「更大、更高分」而已,而是把 Opus 系列進一步推向更適合企業場景的工作型模型:更強的 coding 與 agentic tasks 表現、更穩定的長流程協作能力,以及對複雜專業工作的更一致判斷。
對企業來說,這種升級的意義在於,模型不只是回答得更好,而是更能被放進真實工作流程中。當 AI 要參與程式碼修改、工具操作、跨系統資訊整合、任務分解與長時間執行時,真正重要的是可靠性、上下文延續能力,以及能否被治理與驗證。這正是 Claude Opus 4.8 值得關注的地方。
Claude Opus 4.8 是什麼?
Claude Opus 4.8 是 Anthropic 對 Opus 4.7 的升級版本。根據 Anthropic 官方公告,它在 coding、agentic skills、推理與實務知識工作上都有提升,並維持與 Opus 4.7 相同的常規使用價格。Anthropic 也明確把它定位為更有效的 collaborator,而不是只用來跑單輪問答的模型。
從產品層面來看,Opus 4.8 已可供 Claude 的 Pro、Max、Team 與 Enterprise 使用者使用;對開發者來說,則可透過 claude-opus-4-8 在 Claude API 中呼叫,也可在 Claude Platform、Amazon Web Services、Google Cloud 與 Microsoft Foundry 上使用。這代表它不只是前台產品能力更新,也是一個可以實際被系統整合與導入的企業級模型版本。
為什麼這次更新值得企業注意?
1. 更適合長流程與多步驟 Agent 工作
Anthropic 在這次發布中特別強調 Opus 4.8 在 agentic tasks 與長時間工作上的一致性。對企業而言,這點比 benchmark 分數更重要。因為一個真正能進入流程的 AI Agent,往往不是回答一題就結束,而是要連續閱讀上下文、拆解問題、呼叫工具、調整策略,再將結果整合成可執行輸出。
若模型在長流程中容易跳結論、遺漏條件或中途失去方向,導入成本會非常高。Opus 4.8 的定位,正好回應了企業在這類長流程協作上的核心痛點。
2. Dynamic workflows 代表 Claude Code 正在走向大規模任務編排
Anthropic 這次和 Opus 4.8 一起推出的重點之一,是 Claude Code 的 dynamic workflows。根據官方說明,Claude 現在可以先規劃工作,再在單一 session 中啟動數百個平行 subagents,最後自行驗證結果再回報。這對大型 codebase 遷移、跨模組修正與長鏈路驗證特別有意義。
這個方向值得企業注意,因為它顯示 AI Agent 的競爭點已經不只是模型理解能力,而是「任務編排 + 工具使用 + 驗證機制」。Nexra 在 AI Agent / OpenClaw 的實作上,正是把這些能力視為落地核心,而不是只把模型放進聊天框。
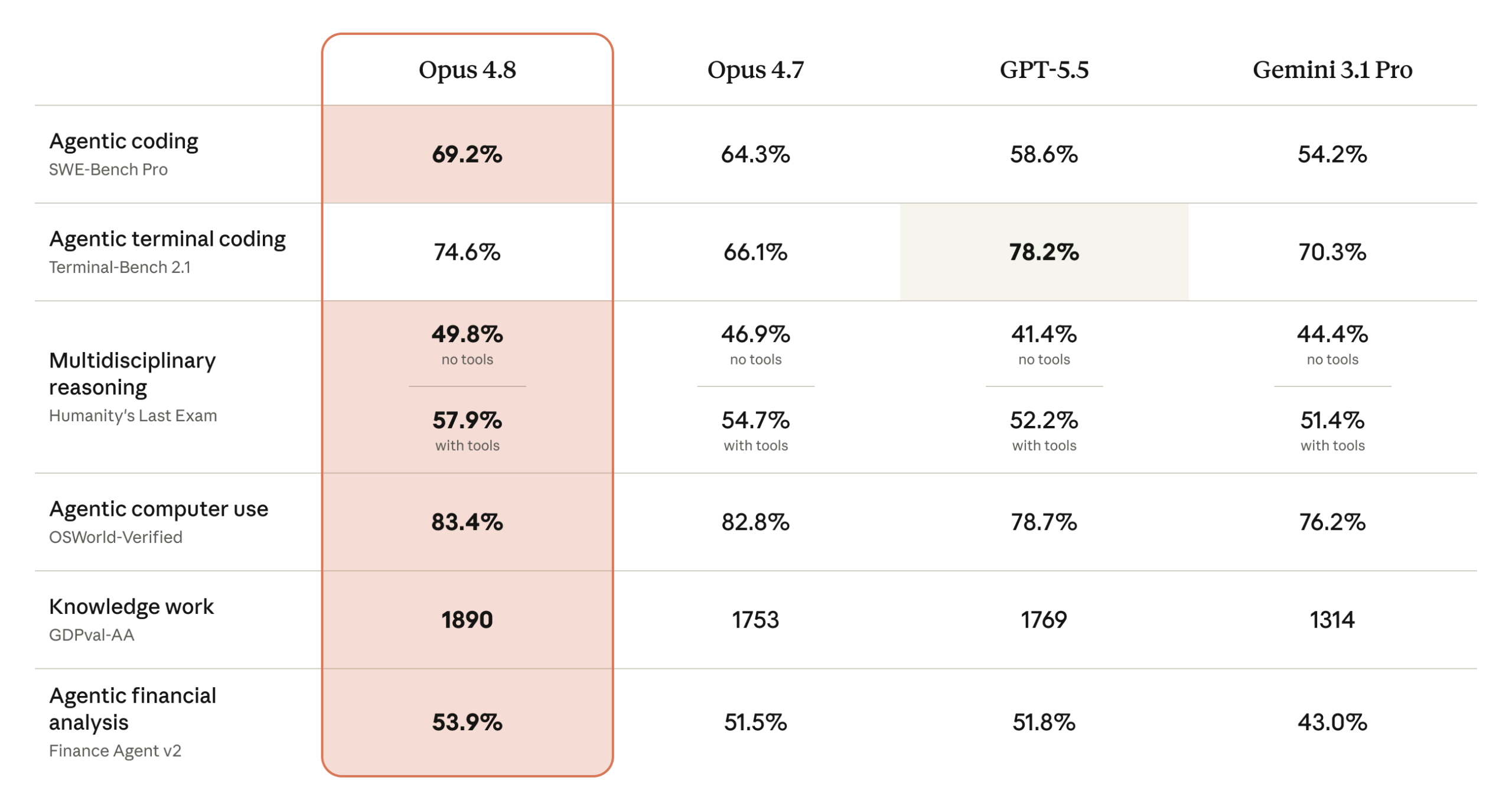
3. Effort control 讓企業更容易做品質與成本分級
Anthropic 同步推出的 effort control,讓使用者可以決定 Claude 要投入多少推理與工作量。較高 effort 下,模型會更頻繁、更深入地思考;較低 effort 下,則能更快回應並更節省額度。這對企業導入非常實用,因為不是所有工作都需要同一種推理深度。
4. 「更誠實」比「更會答」更有企業價值
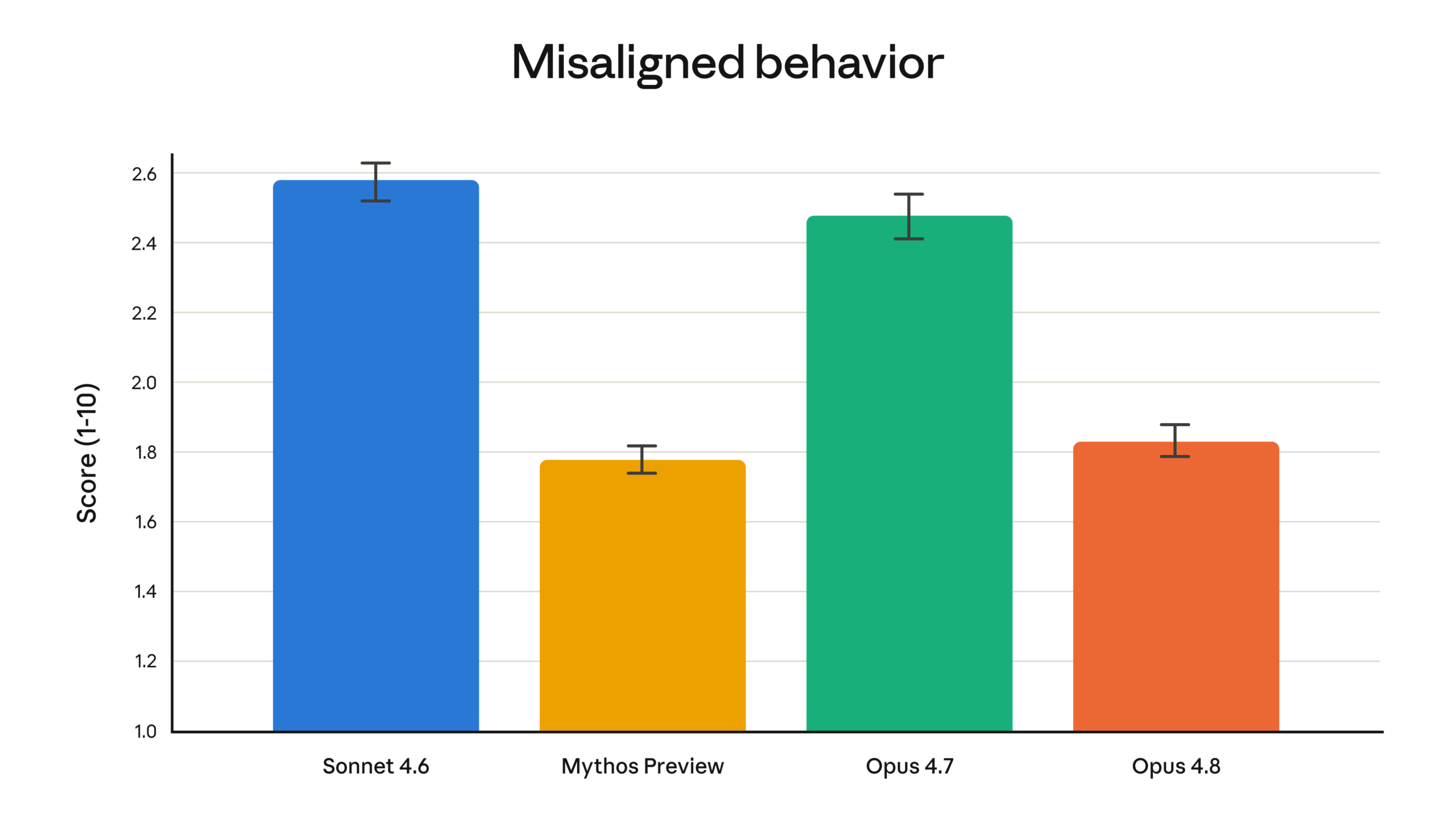
Anthropic 在這次公告中提到,Opus 4.8 的一項明顯進步是 honesty。官方表示,它更願意標記不確定性,也更不容易在證據不足時做出過度自信的結論。Anthropic 的評估指出,Opus 4.8 相較前代,約有 4 倍 的改善,不會默默放過自己寫出的程式碼缺陷。
這類進步對企業環境非常重要。因為在實際導入中,最麻煩的往往不是模型答錯一次,而是它答得看起來很像對的,卻沒有誠實揭露不確定性。若模型能更穩定地回報風險、缺口與需要人工確認的地方,才更適合被納入正式流程。
5. 價格與部署彈性,讓它更容易進入企業決策清單
根據 Anthropic 官方資訊,Opus 4.8 的常規價格與 Opus 4.7 相同,維持在 每百萬 input tokens 5 美元、每百萬 output tokens 25 美元。Fast mode 則是 每百萬 input 10 美元、每百萬 output 50 美元,但在速度上可達 2.5 倍,且比先前模型的 fast mode 便宜 3 倍。對有大量工作流需求的團隊來說,這代表可以用更明確的方式去平衡延遲、品質與成本。
另外,Anthropic 也明確提到 prompt caching 可帶來最高 90% 的成本節省,batch processing 可再節省 50%。若企業本來就有大量重複上下文、標準工作模板或週期性批次任務,這些機制會直接影響導入總成本。
這次更新如何對應 Nexra 的服務方向?
AI Agent / OpenClaw:把模型能力變成可控工作流
Claude Opus 4.8 讓我們看到,前沿模型的競爭已經從「誰更會回答」走向「誰更適合進入複雜工作流程」。這也是 Nexra 在 AI Agent / OpenClaw 實作上的核心觀點:企業真正需要的不是單點回答,而是能連接工具、維持上下文、控管權限、保留紀錄並支援人機協作的任務執行層。
企業 AI 系統整合:接進既有工具與規則
當模型開始參與 Jira、GitLab、資料庫、知識庫、內部後台與工作平台時,導入難點就不再只是模型本身,而是整合與治理。Nexra 可協助企業把 Agent 接入既有系統、設計授權範圍、安排人工審核節點,並讓資料流與操作記錄可追蹤。
LLM 推理 API:依任務做模型與成本分級
Opus 4.8 這次在高 effort、fast mode、prompt caching 與 batch processing 上的設計,很適合拿來思考 API 層的任務分流。哪些請求該走高品質慢速路徑,哪些可以走低延遲批次路徑,會直接影響企業整體推理成本。Nexra 的 LLM 推理 API 服務,就是協助企業把這種模型分級與工作流分級落到可營運的架構上。
企業導入前可以先檢查什麼?
- 任務適配度:你的流程需要的是高判斷力模型,還是高吞吐量模型?是否真的需要 Opus 等級能力。
- 工作流設計:模型會單輪回覆,還是要持續執行多步驟任務、調用工具並回報狀態。
- 成本分級:哪些任務適合高 effort,哪些適合 fast mode、batch 或 caching。
- 資料治理:若要在多系統間調用 Agent,是否已界定資料邊界、權限與審計規則。
- 人工接手機制:當模型表示不確定、偵測到風險或執行失敗時,是否有明確的 fallback 流程。
結語:Claude Opus 4.8 的重點,是更接近能被營運的 AI Agent 模型
Claude Opus 4.8 的價值,不只在於它比前一版更強,而是它更明確地朝著「企業可用」的方向前進:更適合長流程任務、更適合多工具協作、更強調誠實與判斷、更容易做品質與成本分級。這些條件疊加起來,才會讓模型真正從 demo 走向可部署、可治理、可驗證的企業能力。
如果企業正準備評估 AI Agent、Claude API、RAG 知識庫或跨系統整合工作流,Claude Opus 4.8 會是一個很值得納入比較與 PoC 的模型選項。Nexra 可協助企業從需求盤點、工作流設計、模型選型到實際導入,建立更穩定的 AI 協作架構。
資料來源:Anthropic 官方文章 Introducing Claude Opus 4.8 與 Anthropic 官方產品頁 Claude Opus。